坦白说,我非一个 Evernote 资深用户,远比不得笔记本里存了数千条笔记的「老象友」或者英文论坛上「My life is in Evernote」的铁杆粉丝。自己应当是从 2014 年开始才在 Evernote 里面放信息的,而要到后来才知道其实自己的账号是印象笔记。一直以来,我使用这个软件的频率都不高,想起来在里面放点读书笔记或者电脑、编程小技巧。成为 Lumia 用户后,我注意到了 OneNote,并试图用它做过一段时间的笔记——很遗憾,我也没有坚持下来。一方面自己懒,没那么多笔记可以做;另一方面,OneNote 过分自由的设计在整理强迫症眼中非但不是优点,还是额外的心智负担。
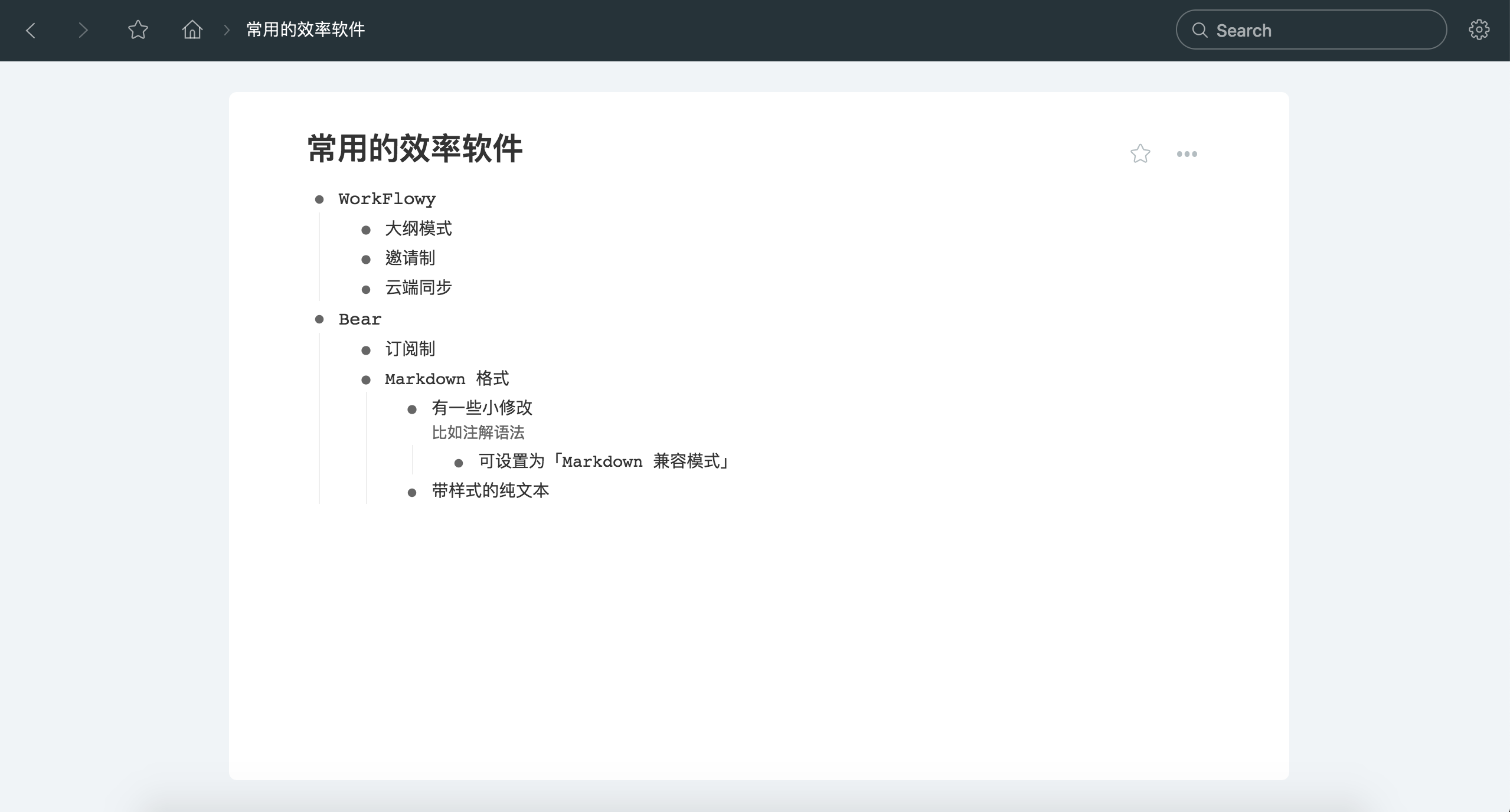
为何很多用户如此热衷于 Markdown?虽然 Markdown 是一个十分钟就能上手的标记语言(特别对于写过 HTML 或者传统电子邮件的人),但它的普及率可能比想象中的低。那位产品经理说得不无道理,很多人接触的第一个电脑上跟文字有关的软件就是 Word,其强大的富文本编辑方式成为这些人脑海中预设的电子编辑模式,太过自然以至于常见「为什么 Word 能做出来的效果你没有?」这般诘问。要求两千块做淘宝的,最起码画个商城界面抄抄设计没问题;要求仿 Word 的,恐怕 Word 的功能他都没多少深入体会。即使强如 Word,在没有标记语言基础的用户手中也常有杂乱错位的排版,更不必说若干笔记软件了。此时选择 Markdown 是明智的。纯文本的简单,未必等于弱小。Evernote 自称包罗万象,却不给用户一个深入掌控笔记内部结构的机会,使人为难。Markdown 虽非最好的答案,的确也是优秀的折衷。
奇妙清单是相当老的 TODO 列表软件了,对普通用户几乎免费。早期对一些要求团队协作的高级功能收费,被微软收购以后就停止高级功能和收费,但也不再更新了。奇妙清单的一大亮点在于全平台支持,从 iOS 到 Windows 乃至 Windows Phone 通通有 App,并且桌面端也是原生,实在不容易。(其实让几个 iOS 程序员兼任开发 Mac App 的任务也不会很难,满大街的 Electron 和 nw.js 实在影响体验)
当然了,任何软件都只是辅助提高工作生活效率的工具,改变自己的工作、学习节奏也一定是一个系统化的、长期的过程。寄改变生活方式的希望于某个软件并不现实。奇妙清单的功能并不复杂,容易上手。如果你此前没有太多折腾数字化工具的经验,可以将它作为入口,管理生活并进一步探索适合自己的方法体系。即使日后你认为它管理任务功能不足,至少作为购物和杂事清单还是不错的。一直都有传言称奇妙清单要倒闭或者停止运营,不过它大概还会在目前的状态下运营较长一段时间。即使要关闭服务器了,因为它提供了完善的 API,所以在发布通知之后,你也有足够的时间一键将已完成和未完成的任务列表转移到其他应用(比如 Todoist)中。当然,微软收购团队之后推出的 Microsoft To-Do (目前尚无 Mac 版)也是一个不错的相似选择。
Ulysses
某种程度而言 Ulysses 不算本文想描述的效率软件,不过实在有很多人推荐过它(包括后面的 iA Writer),所以也值得谈一谈自己对它的看法。Ulysses 是一个有相对久远历史的文本编辑器(好吧,有很多人习惯称呼它写作软件),提供了编辑 Markdown XL(一个扩展的 Markdown 语法)文本和管理文档等一系列功能。如果谈及 Mac 上辅助写作的软件,一定会有人提到 Ulysses,足以说明它在诸多 Mac 用户心中的地位。当然,Ulysses 也有 iOS 版本(尽管第一代 Ulysses 发布的时候好像还没有 iPhone),并提供基于 iCloud 的同步。
我不是 Ulysses 的深度用户(使用 Ulysses 写的字数应该不超过 10000),体验它也主要是因为 SetApp 提供的试用机会。不过它的可定制主题、可定制 Markdown 语法、打字机模式、流畅的写作体验和文档管理等确实令人印象深刻。打开一个全屏界面很容易让人产生写点什么的冲动。(尽管用键盘而不是笔写作长文还是一个需要适应的过程)iOS 版界面相对简单,不过也足以在手机上进行临时的写作工作了。Ulysses 的同步没有使用 iCloud Drive,也就是说保存在文档库中的文档并不是对用户直接可见的(尽管你还是可以在 Mac 上的 Mobile Documents 目录中找到它),这点和 iA Writer 不同,同步也有稍长的延迟。
用 Ulysses 来书写内容当然是足够的,然而写作本身必然也具备痛苦和苦闷,正如这个软件的名字,尤利西斯。值得一说的是它的价格。曾经的 Ulysses 在 Mac App Store 定价 45$(中国区 298¥ 左右),iOS 版定价 25$(中国区 128¥ 左右),算是普通用户需要的软件里面价格相对高昂的了。(我不禁想起当年花了快 400 大洋入的 Photoshop CS6 教育授权,结果一直吃灰)这个价格见仁见智,对很多人来说就是几顿饭的钱。但是你可能也会觉得,它的功能可替代性太强,几乎能写代码的编辑器都支持 Markdown,Mac 上还有好些开源编辑器——我为什么要用它?另外,我也看到过用户反映,Ulysses 在对较长(数千字)文章进行编辑时会有明显卡顿感。这也算是针对写作的文本编辑器的一个通病。(诸如 VS code、Sublime Text、Vim、Emacs 这样的代码编辑软件中倒是很少看到这种现象)
Ulysses 现在的价格是 4.99$(中国区 26¥)一月,如果按年订阅则是 39.99$(中国区 218¥)一年,订阅在同一个 Apple ID 登录的全平台可用。如果是学生,可以得到优惠,6 个月订阅是 10.99$(中国区 73¥)。你可以得到 14 天的免费试用。另外,SetApp 也包含了 Ulysses,对于同一个 Apple ID 登录的 iOS 设备上也可用。
iA Writer
iA Writer,连同 Byword、Quiver 等在内的一系列写作软件,常被当作是 Ulysses 的竞争者。其中 iA 应该是最贵的,也是最老牌的,历经多个版本变迁。本文即是用 iA 写作的。相比 Ulysses 或者其他软件来说,iA 的可定制性很少——只能从两种等宽字体中选择,字体大小也只有三个等级,颜色主题除了日间模式和夜间模式外也不能调。设置页面可以用简陋来形容。
很多人调侃说,自己已经买了的软件,就会想方设法找到它的优点。这话不假。因为潜意识里,对于已经购买的软件,自己就不会把价格纳入考虑因素了。也许对于我,iA Writer 也是这样。每次用 Filco 的红轴键盘和双拼输入法,搭配全屏模式的 iA,写作起来的体验非常好。你可以在 iA Writer 的官网通过视频观看到 iA Writer 的使用方式和界面。
iA 基本支持 MultiMarkdown 语法,除了基本的 Markdown 标记之外,还有注脚、目录、任务列表、表格和 LaTeX 公式等扩展内容。最新的 iA Write 也加入了标签功能。iA 支持类似 Ulysses 和 Typora 上的打字机模式。同步过程是使用 iCloud Drive,意思是每篇文章其实就是一个 txt 格式的文本文件,并且可以在 iCloud Drive 上看到和用其他编辑器编辑。一开始我有点不满意这个做法,认为类似 CloudKit 的数据库同步方式更加易用和干净。不过 iA 支持新建文档的时候自动使用 Markdown 标题作为文件名,这一点也逐渐冲抵了基于文件的同步方式的不便。不过在处理中文全角标点作为标题时,文件名中的符号会被自动转为半角,这是个小问题。另外,可能因为文本文件本身不大,iCloud Drive 的同步还比较流畅。当然,你还可以选择用 Dropbox 同步或者直接在本机的某个目录下保存文档库,在你能够流畅连接 Dropbox 服务的时候,可能体验更好。iOS 端当然也支持对 iCloud Drive 上内容的编辑,并且甚至可以在里面打开你 iA Writer 目录之外的任何文件(即使需要用户自己操作,我也很惊讶 iOS 居然提供了这种接口)。使用基于文件的方式,即使有一天 iA 开发者作死不让你继续使用了,你也至少可以从目录导出你的所有文件。以 Evernote 为代表的数据库模式和若干编辑器代表的文件模式,实在是各有各的好处吧,也许有一天,会有一个兼具两者优点的应用出现也说不定。
iA 的另一个优点在于支持 Windows 和 Android 平台。由于我没有用过,这里就不多讲了。缺点包括统计中文文章字数的时候有问题(Bear 也不对,除了 Word 很少有软件能把这事做好的),语法突出不支持中文(如果你使用英文写作,这倒是个很有意思的功能)。目前看来他们也不想把应用改成订阅制。(Ulysses 遭遇到的阻力应该会冲击很多开发者对订阅制打的算盘)他们的博客上每月会发布一篇文章,其中多数跟产品本身没有关系,质量倒是挺高的。iA Writer 采取买断制,Mac 版价格在中国区是 198¥,iOS 版在中国区是 30¥。Android 和 Windows 的价格没有看到,似乎 Android 采取了免费下载搭配 App 内购买的方式,Windows 版本可以免费试用,购买价格 19.99$。
今年的 WWDC 推出了 iOS 12,其中将原来的 Workflow 和 Siri 整合到了一起,作为一个新的系统功能叫做 Siri Shortcuts。当然,还是需要额外安装。我一直觉得,Siri 是个有些无用的东西。(当然了,所有的语音助手在这一点上都没什么根本区别,而 Siri 的语音合成还明显不如微软的 Cortana)今年 Google 在开发者大会上用语音助手自动点餐的 Demo 震撼了许多人。而苹果终于选择放下曾经的固执,朝着另一个方向,在 Siri 有根本性的突破之前,走一走 Amazon Echo 的路子,让用户自己定义自己的语音助手。
把 Siri 和 Workflow 结合起来,意味着你可以自定义语音指令,驱使手机去帮你做一些事情。这无关所谓真正的「智能」,不过这确实让它变得更加实用了。另外,Workflow 变成 Shortcuts 之后,显得更加官方化,有更多苹果生态下的 App 开发者主动为它提供了接口,这也使得它的功能边界更拓展了一些。
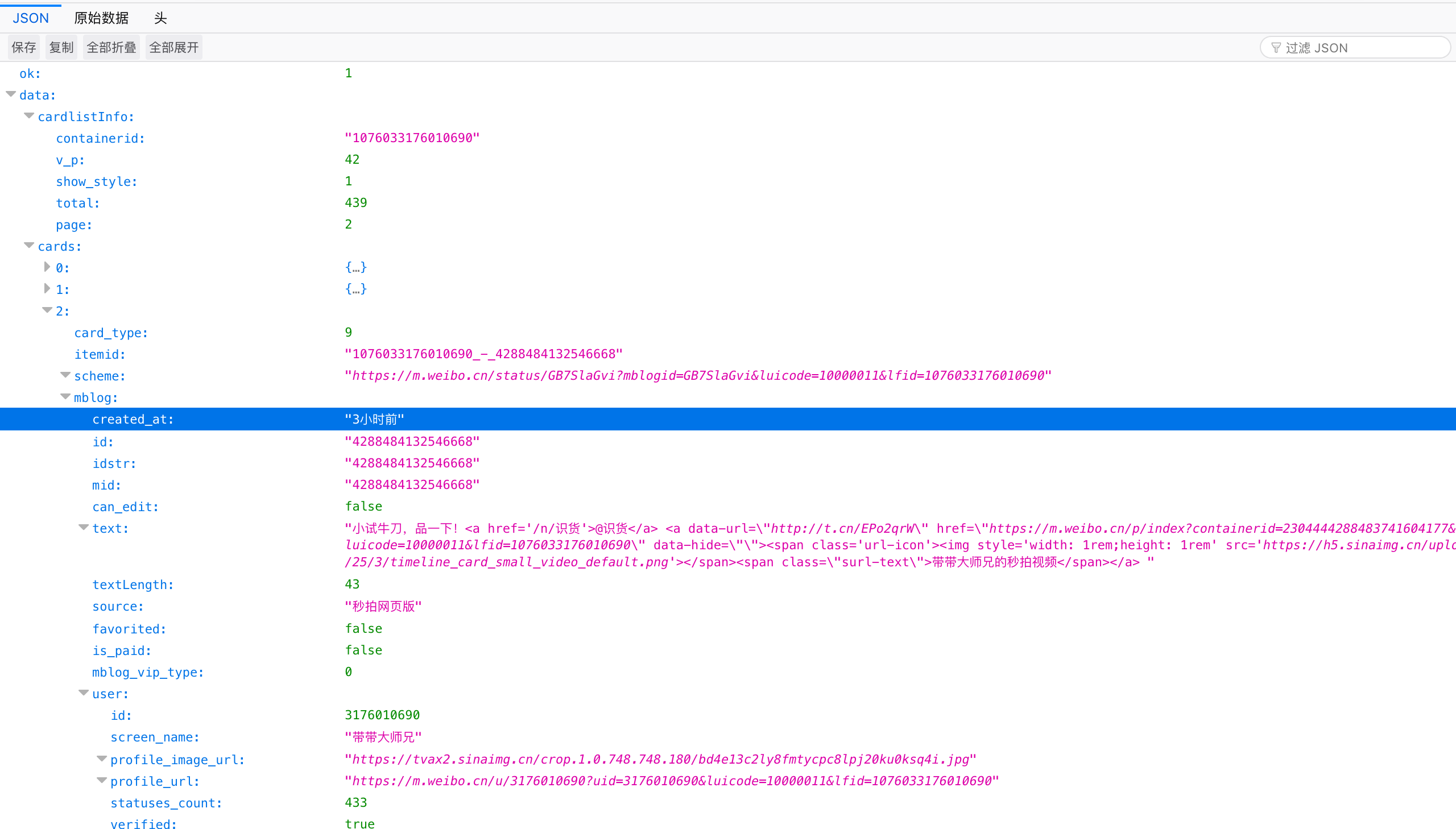
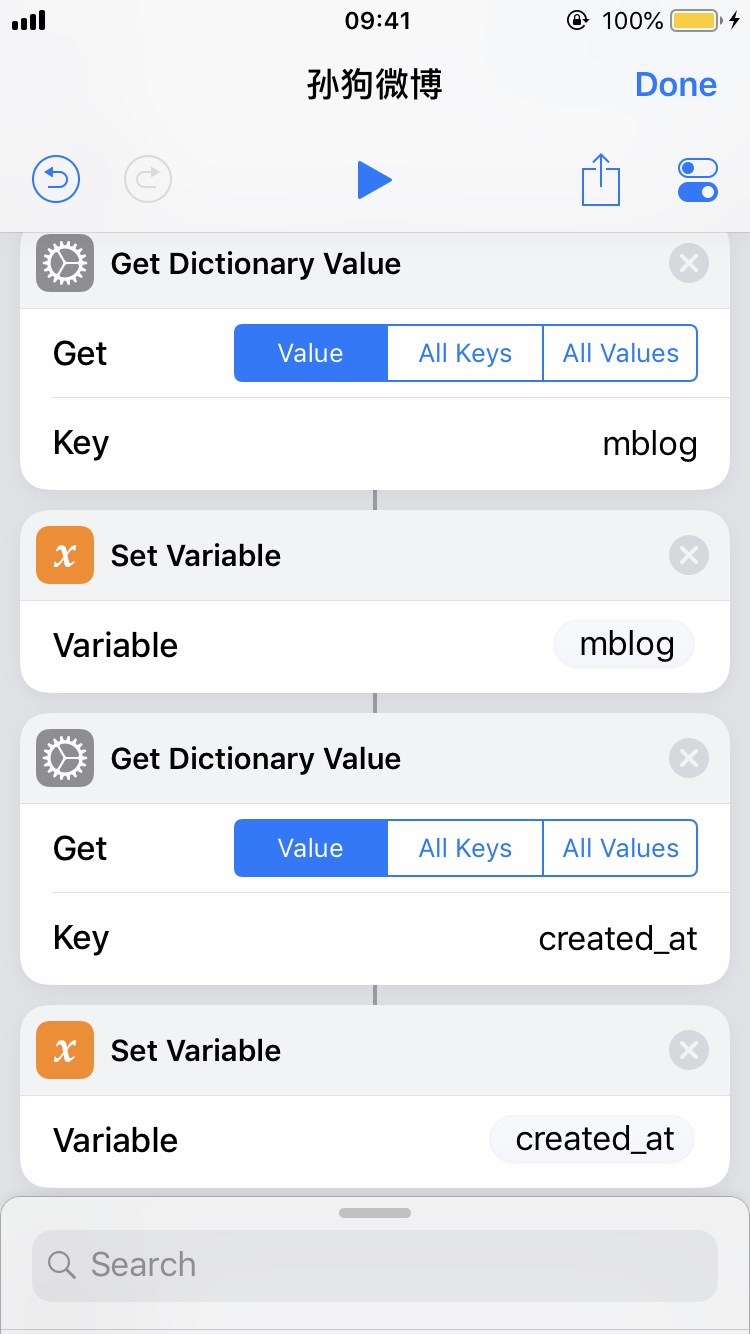
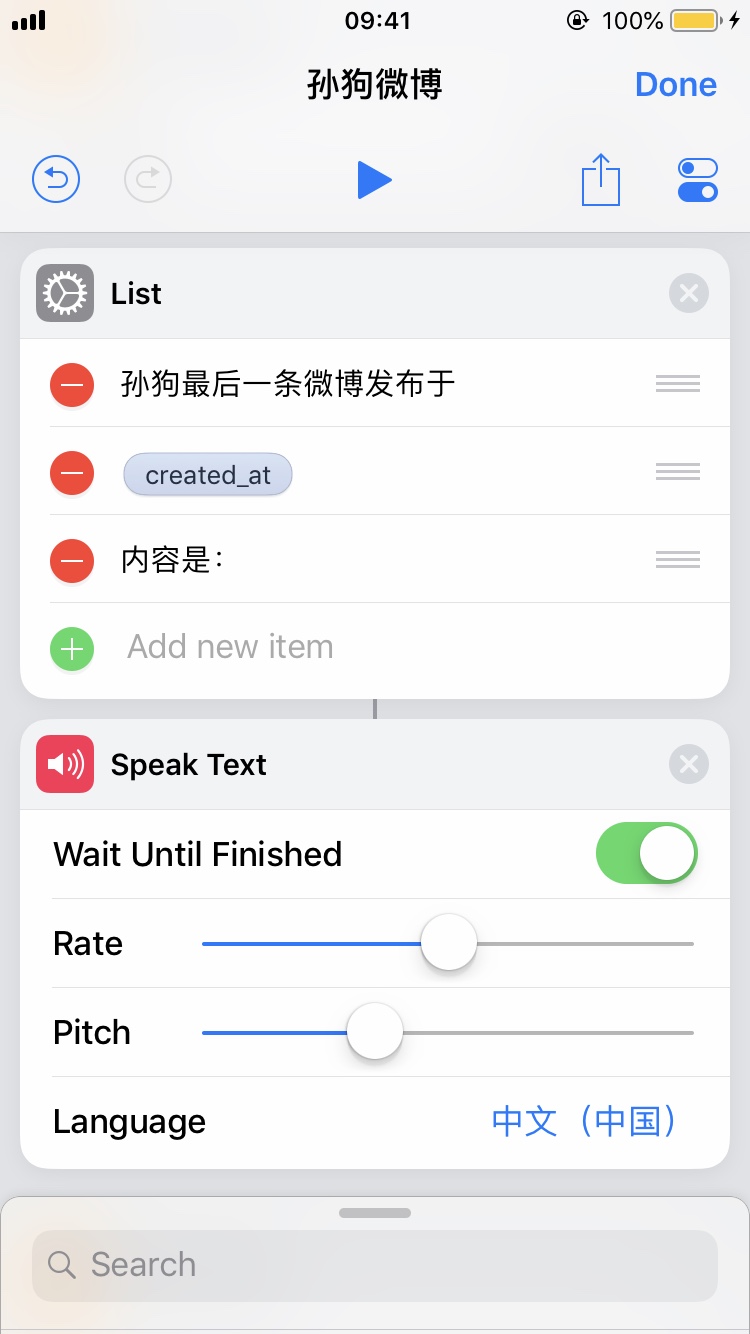
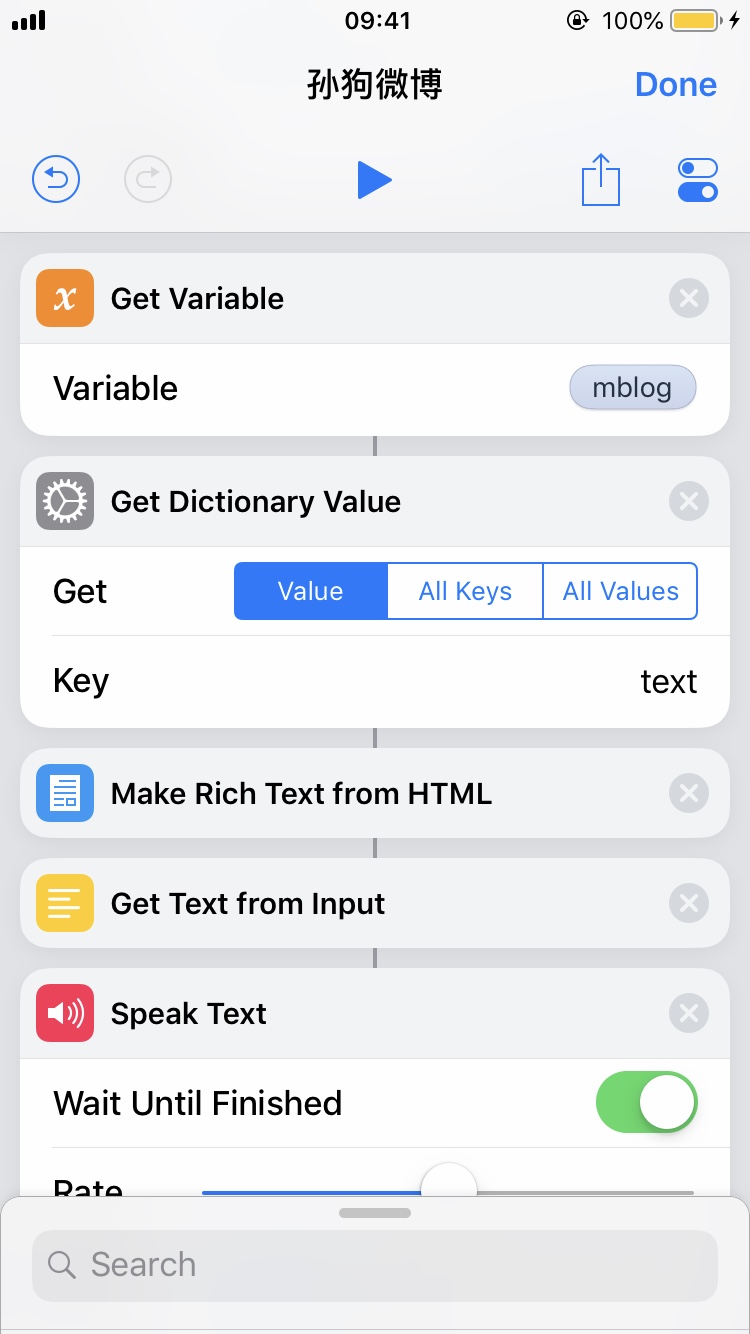
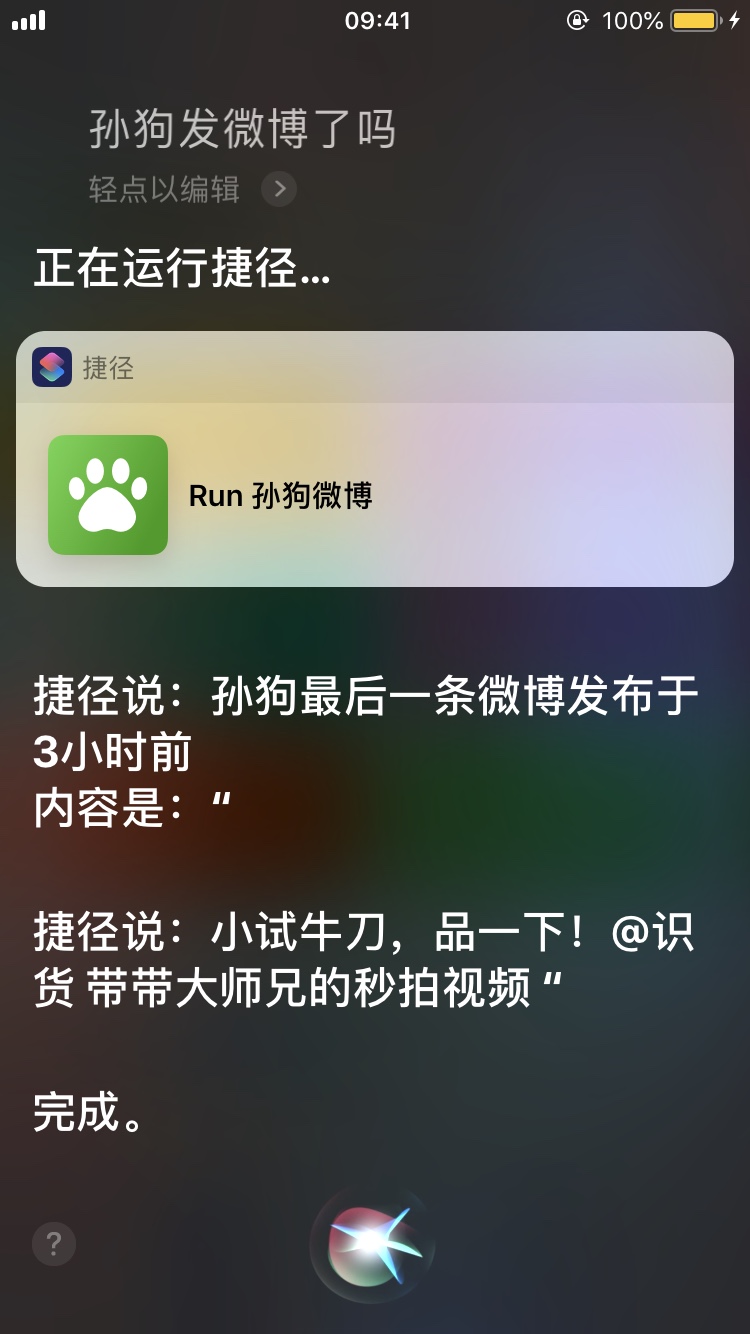
这里是个有趣的例子,我们想要检查一个人有没有发布新的微博。不想每次都点开,甚至像我这样把微博 App 删除了的人连特别关注都没得设置。我们想用 Siri 做到这一点。就以@带带大师兄为例吧。
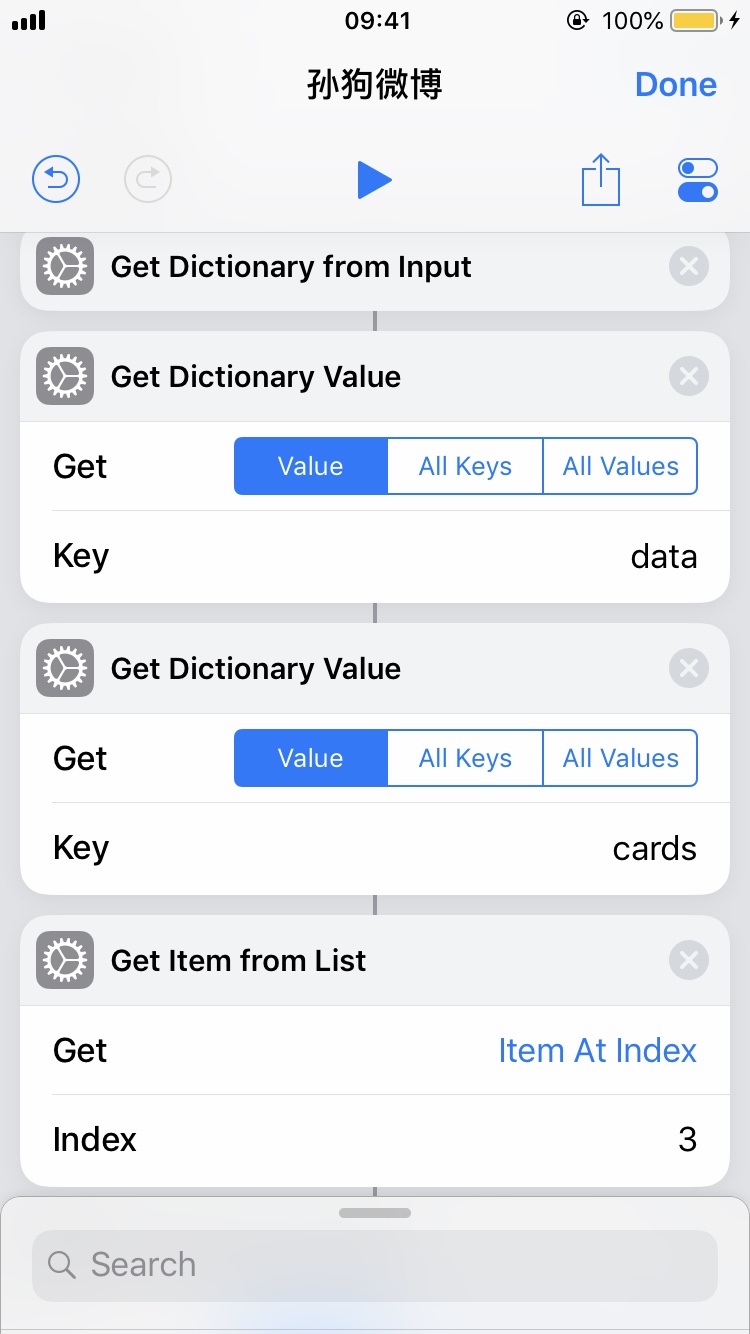
新建一个叫做「孙狗微博」的 Shortcut,在里面随便设置一个喜欢的颜色和图案。
点击进入编辑内容。首先我们需要一个信息源。Shortcuts 有 RSS 的组件,但微博并没有给我们提供官方的 RSS 接口。或者可以在自己的一台 VPS 上写一个脚本定时刷新内容然后暴露一个 API 出来,但这样也太麻烦了。Shortcuts 支持在给定页面上运行一段 JavaScript 代码并返回结果,这个不错。不过这里发现了更好的选择,即微博的 API。这个 API 是从网页调试工具里发现的,带带大师兄的微博内容在这里,以 JSON 格式呈现。
第二点和第一点实际上存在冲突。如果每一个介质都有一定概率被其他人窃取到数据,那么多个备份会让这个概率大大增加。好在信息技术为这一点提供了一条方便的方式,那就是加密。主要的操作系统都提供了可靠的磁盘加密方式,保证磁盘被第三方窃取之后,在没有密钥的情况下,数据不会被获取。现代的文件系统也提供了对单个文件或目录加密的功能。考虑到可移植性,也可以用 ZIP 等压缩格式带有的加密方式或者利用 OpenPGP 软件进行密钥加密。合理运用这些加密方式,基本可以抵御存储器意外丢失造成的数据泄漏风险。当然,早期 Google Chrome 隐私模式会提醒用户「注意你身后的人」。如果想让数据在被检查的时候还能匿迹隐形,做法无非是将内容混淆在普通的文件当中。这不是本文想探讨的主题。
Google 云服务,Google 提供了包括照片、云端硬盘、文档等多款 App 来涵盖手机端云应用的功能,体验还是很不错的。微软和 Google 都是优秀的 iOS 应用开发商。免费的 Google 云盘存储空间是 15 G,值得一提的是,如果同意照片采用「高画质」而非「原文件」存储(也就是可能会稍微损失一点质量),照片的存储空间是无限大。Google 在照片应用中使用了大量人工智能技术,例如搜索 sunset 就会在上传过的库中筛选出夕阳景色的照片。根据 Google 的习惯,照片这类服务存在被砍掉的可能,不过参考 Google Code,真到了时候,还有足够机会迁移。最大的问题是在国内访问不便。
第三种情况就很复杂了。日常办证办卡总会留下点记录,法律不健全的情况下,隐私无法确保安全。令人不安的是,这类信息不像网络账号可以自由创建多个,而是和人身份强绑定的。老司机会告诉你开房时用护照,戴口罩,用现金。不过更重要的,可能是认真评估这类信息泄漏带来的负面后果。比如接到诈骗电话,比如被人将真实身份和网络账号关联起来公开信息……就像防御 XSS 攻击。许多人都喜欢给自己取一个独一无二的特殊 ID 作为各类网络账号的用户名来标识自己,这很棒,只要它不关联到现实身份,或者被人连线挖出某些信息时不会觉得尴尬。
上午第一场报告是一个国内学者做的,大致讲了一下开源和云计算相关方面的趋势和问题。没有什么亮点,或者说没有本人的关注点,所以印象不深刻了。后面是 GNOME 基金会主席的演讲,跟技术无关,说了一下在当今桌面软件依然具有独到的重要性,以及鼓励大家能够多参与到像 GNOME 这样的项目当中去。当然,我是一个 KDE 爱好者。(如果就 Linux 的这群桌面系统而言)
我个人对桌面软件开发知之甚少,因此不太清楚这样的桌面系统的组件的复杂程度和难度。有时候只是单纯地觉得,作为自由软件社区的开发者,靠自发组织是难以维系像桌面软件、浏览器这类众口难调,又期待用户体验的程序了。不同的人看待开源社区自然有不同的视角。除了开源软件本身蕴含的技术价值,开源软件的开发模式本身已经成为一种神奇的现象。传统意义上认为的需要精密严格管理才能完成的项目居然在如此松散的组织条件下也能做到,还能显得生机勃勃。当然,现在的开源生态,包括不同项目各自使用的商业模式,恐怕也是 Richard Stallman 当年未曾想到的。有人将开源软件视作道德标准,有人以质量作为开源软件的核心优势,有人则把开源当作能更好完成项目的开发模型。不得不说这就是开源世界的魅力。其实开源并无什么必然准则,开放扩张自然带来无穷的生命力。
后面的批评包括了对于中国文化的常见看法。比如中国人笃信权威,但是开源社区里没有一个绝对权威。不过我认为这其实是来自于这些中国参与者对开源文化的不了解。日常生活中的会议目的是求同存异,开会各方最后的目的是达成共识然后开始某项进程。而开源社区很多时候不是这样,去参与一个项目的目的很可能就是 Just for fun 或者使自己用着更方便一点。在这种背景下,达成共识是好事但不是必需之事。(苹果毁掉 KHTML 这样的事是道德范畴,个人做不到也不太可能去做)所以无法达成共识的时候,那就分裂。开源社区并没有限制个人在遵守许可证条款前提下分裂项目的权利。如果自用,那无所谓;如果有不同意见,等待自然选择即可。他还提到了开源社区中英语中心的观点,认为这不利于开源的发展。(抱歉,这一点记忆不是很清晰,可能不太准确)也有人认为在 GitHub 上用中文交流可耻。我个人的观点没有那么激进,也不清楚 GitHub 有没有相关的限制。Ruby 社区的邮件列表中也专门有日语板块。对于语言问题不妨用更实用主义的态度,如果一个软件的主要用户和贡献者都是中文使用者,那用中文交流甚至注释都并无大碍。如果项目涉及到来自多个文化的参与者,至少为交流内容提供一份英文副本是有助于它的传播的。这是一个沟通成本的问题,和中文本身没关系。请不要将中文附带上额外的政治意义,也不要因为国内不负责任的译本盛行而认为中文缺乏表达力。坦白讲,以许多程序员(也包括我自己)的语文素养,完全没有资格质疑中文和其他语言在表达能力上的差距。
另外两场演讲,一是如何用开源盈利,二是关于开源运用中拿来主义的心态。内容都比较中规中矩。开源事业能发展到今天,的确也不只是个人开发者的义务劳动能够涵盖的成果,许多商业公司也为开源项目贡献了代码,不少开源项目也找到了盈利模式从而活了下去。典型的例子包括 MySQL 的双重授权,RedHat 的服务收费,一些软件包提供商业的高级版,Google 靠其他业务变现等等。讲者强调了两点:做开源不要忌讳谈钱;所有盈利模式的基础都是用户数量。另一位讲者从文化的角度分析了企业不愿意向上游贡献,不愿意付出资源到开源事业的原因。个人看来,这也跟环境有关。大环境不尊重知识,法律对版权的保护也不到位,外行指导内行,就是这样的结果。不过在可见的未来,这是可以改变的。
后面有一位法律人士在谈 GPL 的传染性问题。很遗憾没有听到。在今天,GPL 协议几乎快到了「人人喊打」的程度,也是令人唏嘘。如果我写了一个自己用的小程序,我会选择用 GPL 发布,因为它代表了自由软件的纯正价值观。但是如果我的目的不是自己日常使用,而是想推广它,恐怕就会考虑 Apache、MIT 或者 BSD 一类宽松的许可证了。作为个人实质上很难去猜测 GPL 或者自由软件基金会的未来,因为 GNU 和 GPL 项目在整个开源世界里所占的比例越来越小,受关注也越来越少。但是没有人能够否认 GNU 带来的工具链在整个体系中的核心地位,大家也几乎都承认是 GPL 保护了 Linux 这么多年来的顺利发展。自由软件的概念也慢慢被开源软件所取代。在软件世界发生的事情不禁使人联想到现实世界:理想主义者作为开拓者推翻了旧的世界,但最后却是由资本和权力接管了世界。靠义务劳动和热情是无法完成如此巨大的事业的。现时开源软件已经是任何软件开发者和公司包括微软都避不开的一个话题了。我们有足够的理由相信开源世界明天会变得更好。然而现实不仅仅是源代码。新的科技引出了新的问题,个人隐私比以往任何一个时代都危险。庆幸还有 Richard Stallman 这样的义士继续为自由与开放而奔走呼号。
到了四月初的时候,听说软件学院要搞一个Android应用开发比赛,所以呢,后端可能还得改。这次大家坐在一起开了个会把需求相对完整地定了下来。不过,还没等得及下手,一切又变了。应用还没开始做呢,就又变卦了。这次是得改变架构,网页和后台不分离。大概就剩一个月的时间了。怎么搞呢?用Ruby on Rails吧。听说,这玩意很快啊。
要说之前,Ruby这个语言我就没有碰过。虽然它和Python我都不熟,不过其实还是用Python相对多一点。但是不行啊,硬着头皮也得上。所幸Rails的文档写得确实不错,我做这个网站的过程中很大程度参考了Ruby on Rails的中文指南。如果有朋友对Rails这个框架感兴趣,非常推荐这一系列文档。同时,也听说Ruby China在国内的技术社区里面是最有氛围的一个了。
# controllers/books_controller.rb
class BooksController
def index
@time = Time.now
end
end
# views/books/index.html.erb
<p>Current time is <= @time %>.</p>